Creative Web Automation: Generate Ad-Free Study Notes
How to use an automated script to grab only the text content off online study notes

For my high-school English book studies, occasionally I referred to online study notes, such as SparkNotes. SparkNotes (and others) provided the content free but split it into multiple small sections with commercial ads. I could live with it; just a lot of pages to click through. My father saw it and created clean combined versions of just the text on these sites using automation scripts.
This article documents how I repeated his work, using raw Selenium in Ruby scripts.
Main Page (for Macbeth)
I’ll use the play Macbeth on Sparknotes as an example.

Each Act ?, scenes ??? link goes to a separate summary and analysis page.
A Section Page:

As you can see, there is quite a number of ads, distractions (and even popups) on the site. My purpose is to create a clean version of just the text.
Automation Design
- Navigate to the main Study Notes Page, and extract the links starting with
Actinto an array. - Define a
pure_content_htmlstring to hold the content - Iterate over the link array, and navigate to each page
- Extract the notes part from the HTML source, and append it to the
pure_content_html. - Generate a new HTML file with the extracted
pure_content_html - Generate a PDF document for printing.
(this step can be done manually)
Implementation
URL: https://www.sparknotes.com/shakespeare/macbeth/
1. Save note pages
First, I used Selenium Webdriver to navigate to the book’s main page and collect all of the links for each section.
links = driver.find_elements(:xpath, "//div[@data-jump='summary']//li/a[@class='landing-page__umbrella__link' and starts-with(text(), 'Act')]")section_links = links.collect { |x| x["href"] }
Then, for each section’s link, visit that page and download the HTML:
the_html = driver.page_source
puts the_html.size # verify HTML was obtained
File.open("tmp.html", "w").write(the_html)There will be several files created: section-0.html , section-1.html , …, section-7.html .
2. Parse the HTML to extract the content
I had some issues getting this to run as part of the Selenium script, it could be done, but not efficiently. So instead, I used a plain Ruby file to open the downloaded HTML files and parse the content with Nokogiri. It is also more convenient as I do not have to open the browser and download the files each time.
I will focus on the first file section-0.html (all eight files have the same structure, i.e, technically the same from our parsing point of view).
# use Nokogiri to parse HTML
require 'nokogiri'the_html = File.read("/tmp/section-0.html")
doc = Nokogiri::HTML(the_html)
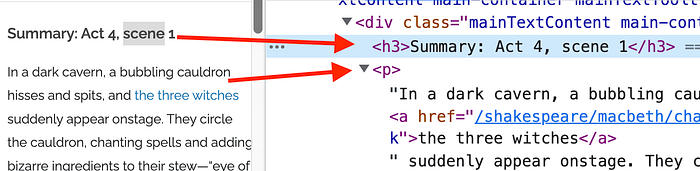
In the screenshot below, the main content we are interested in (Act, Scene numbers & the summary) are under the divwith the class mainTextContent and the <h3> and <p> tags. So we will use Nokogiri to only extract these tags out.
the_pure_content_html = "<html><body>"
elem_main_content = doc.xpath("//div[contains(@class, 'mainTextContent')]")# only keep h3 and p tagged elements
elem_main_content.children.each_with_index do |x, idx|
if x.name == "h3"
the_pure_content_html += ("\n<br/><h3>" + x + "</h3>\n")
elsif x.name == "p"
the_pure_content_html += ("\n<p>" + x + "</p>\n")
end
endthe_pure_content_html += "\n</body></html>"
3. Filter out unneeded links.
There are some additional <p> tags that we don’t want to keep in the clean version, such as links like the below:

We can filter these links out.
# revised filter
if x.name == "h3"
the_pure_content_html += ("\n<br/><h3>" + x + "</h3>\n")
elsif x.name == "p"
if x.to_s.include?("<p><a href") || x.to_s.include?("<p><span")
# skip additional links
else
the_pure_content_html += ("\n<p>" + x + "</p>\n")
end
end4. Combine all section files.
After confirming the first section is done properly, we can simply put it into a loop to process all the section files together.
the_pure_content_html = "<html><body>"
8.times do |idx|
doc = Nokogiri::HTML(File.read("/tmp/section-#{idx}.html")
# ...
the_pure_content_html += ... # see above
end
the_pure_content_html += "\n</body></html>"the_pure_content_html now only has all the clean content (Section headings and summary). Save it into a HTML file.
File.open("/tmp/clean-vers.html", "w").write(the_pure_content_html)5. Optimize and Print out
Just open the /tmp/clean-ver.html in a browser, and print it to PDF. The output will be like this:

It’s clean — no distracting advertisements or popups! We can improve further by adding inline styling.
the_pure_content_html = "<html><head>
<style>
body {background-color: #FFF;
font-family: Verdana, Helvetica, Arial;
font-size: 14px; }
h3 {font-size: 15px; color: blue;}
</style>
</head><body>\n"
Complete Script
Script 1 — Save the notes (multiple) to separate HTML files
Using Raw Selenium WebDriver
it "Download Macbeth Sparknotes" do
driver.get("https://www.sparknotes.com/shakespeare/macbeth")# Main Page, get all section links
links = driver.find_elements(:xpath, "//div[@data-jump='summary']//li/a[@class='landing-page__umbrella__link' and starts-with(text(), 'Act')]")
section_links = links.collect { |x| x["href"] }
section_links.each_with_index do |current_section, idx|
driver.get(current_section)
the_html = driver.page_source # get page html
File.open("/tmp/section-#{idx}.html", "w").write(the_html)
end
end
Script 2 — Parse and generate the clean HTML version
Using Nokogiri ruby gem to parse the HTML.
require 'nokogiri'
the_pure_content_html = "<html><head>
<style>
body {background-color: #FFF;
font-family: Verdana, Helvetica, Arial;
font-size: 14px;}
h3 {font-size: 15px; color: blue;}
</style>
</head><body>\n"8.times do |idx|
the_html = File.read("/tmp/section-#{idx}.html")
doc = Nokogiri::HTML(the_html)
elem_main_content = doc.xpath("//div[contains(@class, 'mainTextContent')]")
elem_main_content.children.each_with_index do |x, idx|
if x.name == "h3"
the_pure_content_html += ("\n<br/><h3>" + x + "</h3>\n")
elsif x.name == "p"
if x.to_s.include?("<p><a href") || x.to_s.include?("<p><span")
# skip
else
the_pure_content_html += ("\n<p>" + x + "</p>\n")
end
end
end
endthe_pure_content_html += "\n</body></html>"
File.open("/tmp/clean-ver.html", "w").write(the_pure_content_html)
